A new multiple subtraction method uses the attributes of predicted multiples, not the multiples themselves.
Manhong Guo, Young Kim, Satyakee Sen, Jim Xu, Jing Xie and Bin Wang, TGS-NOPEC Geophysical Company.
Multiple reflections of seismic waves off of the seafloor have been keeping processing experts busy for years. To get a clear image of the subsurface, the true or primary seismic reflection must be preserved while the multiple reflections are removed - no easy task. Removing surface-related diffracted multiples in 3D seismic data is a challenging but necessary process to ensure accurate event placement.
One solution that has seen substantial progress is the use of predicted multiples to subtract the surface-related multiples. There have been some excellent techniques developed for predicting multiples, such as convolution-based or wavefield-extrapolation-based approaches. However, difficulty stems from the fact that many existing techniques try to match the predicted multiples to the multiples in the data by either adaptation or pattern matching. The issue with these prediction techniques is that they change the waveform of the predicted multiples, and this makes it very difficult to perfectly match the waveform of the predicted multiples to that of the multiples in the data.
The R&D team at the authors’ company realized that the matching process was altering the data in such a way that multiple subtraction was really not as reliable as it could be. Our solution was to develop a new technique for subtracting multiples without the matching process that could provide more accurate results.
The new approach simplifies the multiple subtraction process by only using specific attributes of the predicted multiples, namely, dip and Average Absolute Value (AAV) along the dip. Instead of subtracting adapted or matched multiples, the subtracted multiples are directly estimated from the data using the dip and AAV of the predicted multiples. This method eliminates the complicated matching step and provides a more accurate preservation of the primary reflections. We have tested this method on field data, and the results have been that the new method removed the multiples while preserving the primaries better than conventional adaptive-subtraction methods.
MULTIPLE SUBTRACTION METHODS
For background, the two common approaches for predicting multiples - convolution-based prediction1 and wavefield-extrapolation-based prediction2 - were compared and well summarized by Matsen and Xia.3 Both prediction methods can accurately predict the timing of multiples. However, they are not ideal because they both alter the waveform of multiples.
Convolution-based approaches change the waveform by doubling the source wavelet spectrum in the frequency domain. In addition, interpolated traces are used to generate missing source-receiver pairs at the bounce points under the water surface, and these traces may not have the same waveform as the missing traces.
Wavefield-extrapolation-based approaches also change the waveform; the only way to avoid this is to use a perfect reflectivity model, which is impractical to obtain. These waveform changes make subtracting multiples in the data using the predicted multiples a challenging task.
One common approach for subtracting multiples using predicted multiples is adaptive subtraction.4 Adaptive subtraction tries to match the waveform of the predicted multiples to that in the data in both amplitude and phase in a window. This technique provides cause for concern for a couple of reasons. First, if the window is small enough to include only multiples, the window may not be able to provide enough statistics to design a reliable filter. Conversely, if the window is large, it may contain primaries and other noise to limit the adaptation process.
Another approach to multiple subtraction is based on pattern matching.5 One designs a Prediction Error Filter (PEF) for the primary by deconvolving the PEF of the data with that of the predicted multiples. Comparison of adaptive subtraction versus pattern matching is well-documented by Abma et al.6 They report that a pattern-matching technique also has its disadvantages. This method tends to leave much residual multiple energy and to weaken the primaries where the predicted multiples overlapped the primaries.
NEW MULTIPLE SUBTRACTION METHOD
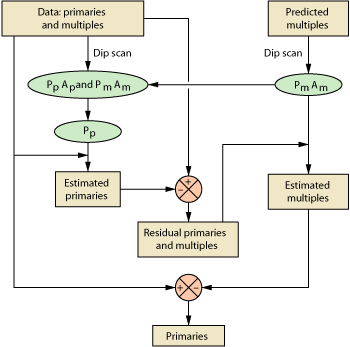
The new approach developed by the authors avoids the matching process altogether, which may have been the main source of difficulty in previous approaches. Figure 1 shows a flow diagram of the new method using the dip and AAV of the events in the data and in the predicted multiples. It consists of two steps. The first step is to determine whether a given sample in the data belongs to a primary or a multiple. In the second step, the multiples in the data are estimated and subtracted from the data.
|
|
|
Fig. 1. The new method uses dip and Average Absolute Value of the data events and in the predicted multiples. Step 1 determines whether a given sample in the data belongs to a primary or a multiple. Step 2 estimates the multiples and subtracts them.
|
|
The dip scan is used to determine the dip of the events in the data that contains primaries, multiples and other noises. The dip scan is also used to determine the dip of the events in the predicted multiples. Next, the dip of the events in the data is compared with the dip of the events in the predicted multiples to separate the dip of the primaries. If the dip at a sample point in the data is sufficiently different from the dip at the same sample location in the predicted multiples, the sample in the data is considered as a primary. On the other hand, if they are similar, then that sample in the data is considered a multiple. In addition, the AAV is another criterion used to distinguish the primaries from the multiples, particularly when the dips are similar. Because of spurious noises in the predicted multiples, the dip at a sample point in the predicted multiples can be similar to that of the sample at the same location in the data. However, the AAV along the dip in the predicted multiples should be much smaller than the AAV along the same dip in the data. In such cases, the sample is regarded as a primary.
In the second step, assuming the waveform does not change much over a few traces, the primaries are estimated by averaging over a few traces along the dip. Then the estimated primaries are subtracted from the data to obtain a new data set that contains all the multiples. The new data set may also contain some residual primaries that were not properly accounted for in the previous estimation step. Using the dip of the events in the predicted multiples, the multiples from the new data set are estimated or reconstructed by averaging over a few traces along the dip of the multiples. These estimated multiples are subtracted from the data. Reconstructing the multiples using the data set from which most primaries are removed allows for more reliable estimation of the multiples in the data.
Note that, instead of generating a filter that will try to match the predicted multiples to the multiples in the data, the multiples in the data are directly determined using the dip of the predicted multiples. In other words, the predicted multiples are used only to determine the dip of the multiples in the data. In doing so, one can avoid the step of matching the waveform of the predicted multiples to that of the multiples in the data.
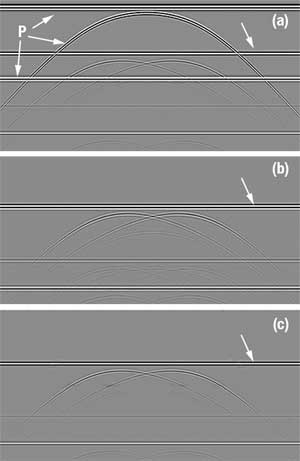
Figure 2a shows a common offset synthetic data set that contains two flat, primary events and one primary diffraction indicated by P and white arrows and their multiples. Figure 2b displays the predicted multiples using wavefield extrapolation. Basically, a round trip was added to each depth in the migrated section (not shown). Note that the waveform of the predicted multiples is different from that of the data. By comparing the dip and AAV of the event in the data and those of the corresponding event in the predicted multiples, the primaries and their dip can be identified. The primaries are estimated by averaging over a few traces along the dip in the data and subtracting them from the data. This step results in a new data set that mostly contains the multiples in the data. This data set is used to determine the multiples by averaging over a few traces along the dip of the multiples.
Using the data set that mostly contains the multiples provides an advantage over using the original data set for determining the multiples. Since the original data includes the primaries or other noises, averaging over a few traces along a multiple dip can be affected by the primaries or other noises. Figure 2c shows the estimated multiples that will be subtracted from the data. Note that the waveform of the estimated multiples is the same as the waveform of the multiples in the data. The white arrows in Fig. 2 indicate a) the multiple in the data, b) the predicted multiple and c) the reconstructed multiple.
 |
|
Fig. 2. a) A common offset section, b) the predicted multiples and c) the reconstructed multiples.
|
|
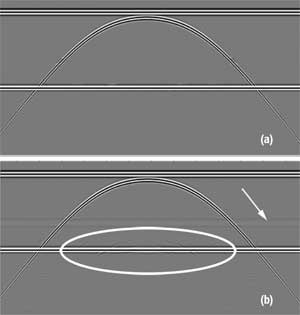
Figure 3a shows the result of subtracting the estimated multiples from the data. Note that all the multiples are subtracted properly. Figure 3b displays the result of adaptive subtraction. The flat primary where a diffracted multiple coincides with the primary in the data is distorted. There is a difference between the waveform of the predicted multiples and the waveform of the data where the primary and the diffracted multiple are overlapped. This difference prevents adaptation from perfectly fitting only the multiples in the data. In addition, a noticeable amount of multiple energy is left after adaptive subtraction (indicated by a white arrow).
 |
|
Fig. 3. Synthetics: a) subtraction using the attributes of the predicted multiples, and b) conventional adaptive subtraction. Note the residual multiples (white arrow) and in the ellipse.
|
|
RESULTS
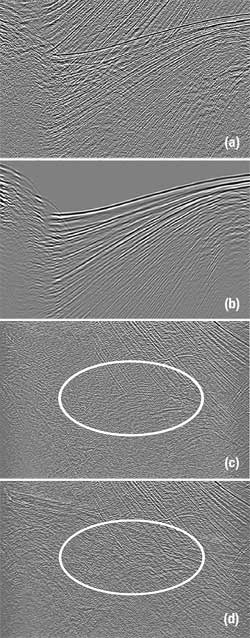
Figure 4a shows a common offset section of an inline from a marine 3D survey. The data were acquired using six streamers of 9-km length with a cable spacing of 160 m in the deepwater Gulf of Mexico. Because of severe feathering, each shot gather had to be regularized on a uniform grid with an inline spacing of 12.5 m and a crossline spacing of 80 m. A preliminary depth-migrated cube was used as a reflectivity model and the corresponding velocity model was used as a velocity model for wavefield extrapolation to predict the multiples. To prevent wraparound noises, the computation grid was extended. The nominal distance of the computation grid in the crossline direction was 4 km. Because of severe feathering, a computation grid wider than 8 km in the crossline direction was used for some shots. About 6 km in the inline direction was also padded to avoid wraparound noises in the inline direction.
 |
|
Fig. 4. a) Input, b) predicted multiples, c) attribute-based subtraction and d) adaptive subtraction.
|
|
The difference between the dip of the primaries and the dip of multiples is more evident in the common offset domain than in the common shot domain. For this reason, the method was applied in the common offset domain. Figure 4b shows the predicted multiples by extrapolating the shot gathers to a depth of 3,000 m, which is deeper than the deepest top of the salt, and back to the surface. This depth ensures that wave field extrapolation can predict both source- and receiver-side multiples bounded by the water surface and any reflectors down to the depth of 3,000 m. Note that the location of predicted multiples is precise, but the waveform of the predicted multiples is quite different from the waveform of the multiples in the data.
Figure 4c shows the result after subtracting the multiples using the new method. Note that the first-order water-bottom multiples and their peg legs are well suppressed. After subtracting the multiples, many steeply dipping primary events, as well as gently dipping reflections (see the events inside the ellipse), are well-retained, which were previously masked by high-amplitude multiples. For comparison, we used an adaptive subtraction method and displayed the results in Fig. 4d. The subtraction was somewhat mild to preserve the primaries. As a result, a noticeable amount of multiple energy was left. Many steeply or gently dipping primary events are still masked by residual multiples. If the adaptation parameters are tightened, more multiples can be subtracted, but some primaries could also be removed.
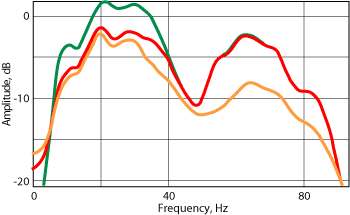
Shown in Fig. 5 are the spectra of the data shown in Fig. 4. The green curve shows the spectrum of the input data, the red curve shows the spectrum of the adaptive subtraction, and the brown curve shows the spectrum of the attribute-based subtraction. The notch in the input spectrum is due to towing the streamer at a depth of 18 m to retain the low-frequency components of the data. These spectra illustrate the performance of the two subtraction techniques. The adaptive subtraction method failed to match the predicted multiples to the multiples in the data in the high-frequency range. Basically, there was no subtraction of high-frequency components. On the other hand, the attribute-based subtraction worked well on all frequency components.
 |
|
Fig. 5. Amplitude spectra of the data shown in Fig. 4.
|
|
CONCLUSIONS
Adaptive subtraction approaches have been a main tool for subtracting the predicted multiples from the data. However, matching can be either too aggressive or too mild. When it is too aggressive, the multiples can be eliminated, but many primaries are also partially removed. On the other hand, when matching is too mild, most primaries are preserved, but much of the multiple energy also remains.
A new method using the attributes of the data and predicted multiples avoids the matching of the predicted multiples to the multiples in the data. Instead, it uses the dip and AAV at each sample in the data and in the predicted multiples to differentiate the primaries from the multiples. Once it is identified as a primary, the primary is estimated as an average of the samples along the dip over a few traces.
These estimated primaries are subtracted from the data to make a new data set, from which the multiples are estimated by summing over a few traces along the dip of the multiples.
The new method works well for most multiples except when a primary and a multiple overlap each other with the same dip and a similar AAV. For example, a flat primary and the apex of diffracted multiples can overlap with a flat dip. In such cases, one may determine the dip by scanning over a large number of traces such that the AAV of the primary will be much higher than that of the diffracted multiples.
The current tests on field data show favorable results for the new method; the multiples were removed and primaries were preserved better than conventional adaptive subtraction methods. The R&D team plans to continue improving the methodology by exploring some other attributes, such as frequency, which could help further separate primaries from multiples. The team is exploring the possibility of combining this method with the traditional adaptive subtraction process. These new techniques will continue to be tested and eventually implemented, along with many other efficiency-improving methods for clarifying subsurface images. 
ACKNOWLEDGMENTS
The authors would like to thank James Cai and Zhiming Li for their technical input and Shannon Morolez for editing.
LITERATURE CITED
1 Verschuur, D. J., Berkhout, A. J. and C. P. A. Wapenaar, “Adaptive surface-related multiple subtraction,” Geophysics, 57, 1992, pp. 1,166-1,177.
2 Pica, A., et al., “3-D surface-related multiple modeling, principles and results,” Society of Exploration Geophysicists, Expanded Abstracts, 2005, pp. 2,080-2,083.
3 Matsen, K. and G. Xia, “Multiple attenuation methods for wide azimuth marine seismic data,” Society of Exploration Geophysicists, Expanded Abstracts, 2007, pp. 2,476-2,479.
4 Verschuur, D. J., Berkhout, A. J. and C. P. A. Wapenaar, “Adaptive surface-related multiple subtraction,” Geophysics, 57, 1992, pp. 1,166-1,177.
5 Spitz, S., “Pattern recognition, spatial predictability, and subtraction of multiple events,” The Leading Edge, 18, 1999, pp. 55-58.
6 Abma, R., et al., “Comparisons of adaptive subtraction methods for multiple attenuation,” The Leading Edge, 24, 2005, pp. 277-280.
|
THE AUTHORS
|
| |
Manhong Guo received an MS degree in computer science from the University of Houston and in geology from the Institute of Geology, China. In 2001 he joined NuTec Energy, which became a part of TGS-NOPEC Geophysical Company, where he is a Senior Research Geophysicist.
|
|
| |
Young Kim is Chief Scientist at TGS-NOPEC. He earned a PhD degree in electrical engineering from the University of Texas at Austin. Upon retiring from ExxonMobil, he joined TGS-NOPEC Geophysical Company to build a new R&D team in 2005.
|
|
| |
Satyakee Sen received an MS degree in geophysics from Pennsylvania State University. He joined TGS-NOPEC Geophysical Company in 2006 and has been conducting research on multiple estimation and suppression. He is a Research Geophysicist.
|
|
| |
Jim Xu received his PhD degree in aerospace engineering from the University of Texas at Austin. Jim worked for Atmospheric & Environmental Research, Inc., and Shell International E&P. He joined TGS-NOPEC Geophysical Company in 2005 to conduct research in multiple estimation and suppression. He is currently a Processing Geophysicist.
|
|
| |
Jing Xie worked for WesternGeco and GeoTomo and joined TGS-NOPEC Geophysical in 2005, where he is a Senior Software Engineer. He earned his PhD degree in petroleum engineering from the University of Texas at Austin.
|
|
| |
Bin Wang earned a PhD degree in geophysics from Purdue University in 1993, and an MBA from Southern Methodist University in 2001. He started his career with Mobil Oil in 1993, and joined TGS-NOPEC in March 2007. He is now general manager of R&D at TGS-NOPEC.
|
|
|

