Advancing artificial intelligence and machine learning
For decades, the oil and gas industry has focused on mechanical, engineering and geological factors to assess and manage exploration, drilling, completion and production operations. Those factors will still weigh heavily in decision-making, but they are now being supplemented by emerging technology in Artificial Intelligence (AI) and Machine Learning (ML).
The National Energy Technology Laboratory (NETL) is heavily involved in increasing the role of AI and ML in upstream operations. The decision to pursue these capabilities was the result of a request by the U.S. Department of Energy, Assistant Secretary for Fossil Energy, Steven Winberg, to survey the oil and gas industry about AI and ML. The resulting survey found that a lot of industry data were collected but only a fraction of the data is utilized. Emerging sources of data, such as those from fiber optics, are now becoming available and can provide rich, continuous datastreams. A conference of industry, academic and government sources was subsequently convened, under the leadership of Carnegie Mellon University, and the AI/ML initiative was begun.
With the increased footprint of onshore unconventional activity, the industry has begun to rely more and more on rapidly increasing datasets, in which drilling operations can produce up to 15 terabytes of data per well. Onshore companies are managing 25,000 to 40,000 wells via enterprise systems, and they want to spend more time analyzing data than managing it. Due to the limitations of current data infrastructures, however, much of the data being collected by a rapidly expanding array of sensors is not retained and analyzed.
Some estimates suggest that companies process only 20% of the data that they collect. Recent reports indicate that large onshore oil and gas companies are attempting to integrate big data analytics and realizing success when pairing their industry expertise and data science professionals. In one case, over $100 million of increased production, representing a 60% rise in well performance, was realized in one year.
Data analytics. AI and ML are driven by data analytics (DA). DA is a process used to identify hidden patterns and relationships in large, complex and multi-variate datasets. The application of data analytics involves three key elements:
- Data organization and management: ensuring that the right data are collected, retrieved and stored for given analyses
- Analytics and knowledge discovery: software-driven modeling to capture input-output relationships
- Decision support and visualization: sharing results with decision-makers, as well as streamlining repetitive tasks.
Artificial intelligence or AI, notes NETL Director, Dr. Brian Anderson, refers to software technologies that make a computer act and think like a human, saving time and increasing efficiency. Researchers are discovering how useful AI can be in energy applications. For example, AI is making a significant impact in the way that we analyze critical data for decision-making related to operation of power plants and upstream equipment. AI innovations are improving condition-based monitoring of operational conditions; facilitating new levels of cybersecurity to protect energy assets; and spearheading innovative diagnostic inspections, using AI-enabled robots for automated non-destructive evaluation and repair of power plant boilers.
Machine learning typically falls under three prominent categories: supervised learning, unsupervised learning, and reinforcement learning, Fig. 1. Prominent ML algorithms and approaches available are aligned specifically to these categories. Working in conjunction with AI, ML is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions. The machine learning process has three steps: 1) identification of patterns from historical “training” data; 2) the construction of behavioral models from the patterns, validated using “test” data; and 3) the identification of “learning-based” recommendations. A machine learning algorithm can make predictions, based on learning a pattern from sample inputs. The algorithm does not rely upon predefined program instructions. Some non-oilfield examples include speech recognition and web search algorithms, self-driving car control software, and human genome research software.
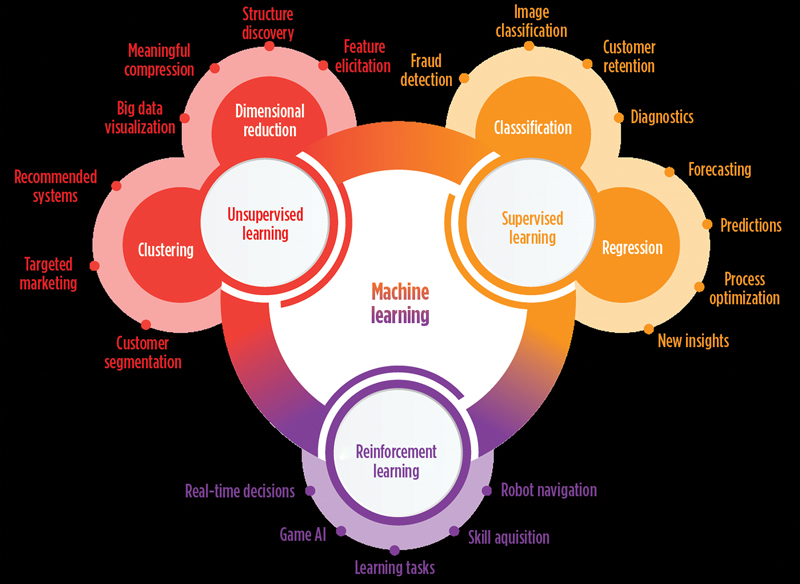
ML applications are being explored for use in subsurface energy resource recovery, because ML can capture the behavior of complex systems through complex-but-rapid empirical models, capturing knowledge and quickly providing it to decision-makers with minimum labor, dramatically lowering cost of processing monitoring data. In addition, ML, in combination with sensor and control systems, can improve efficiency in reservoir management and improve risk management, creating safer conditions and improving environmental risks. ML underpins the analytics and knowledge discovery aspects of DA.
AI and ML are enabled by computing power. NETL is home to Joule 2.0, which is among the fastest, largest and most energy-efficient supercomputers in the world. A recent $16.5-million upgrade boosted Joule’s computational power by nearly eight times, enabling researchers to tackle more challenging problems than ever before, as they work to make more efficient use of the nation’s vast fossil fuel resources.
The upgrade to Joule 2.0 boosted the system’s computational power to 5.767 PFLOPS [A petaflop is the ability of a computer to do one quadrillion floating-point operations per second (FLOPS). A petaflop computer requires a massive number of computers working in parallel on the same problem.], meaning that it can perform more than 5 quadrillion calculations per second. That’s equivalent to processing power of roughly 54,658 desktop computers, combined.
Joule 2.0 Facts:
- Joule’s total memory is 271 terabytes, or about the same as 68,033 desktop computers.
- Joule 2.0 can store 11.6 petabytes of data, which equate to almost 1,181 copies of the information stored by the Library of Congress.
- Joule 2.0 has a network bandwidth of 83.2 terabytes per second—enough capacity to simultaneously stream 10.4 million high-definition movies on Netflix.
- A gifted mathematician working 40 hours a week for 50 weeks per year would take about 55.9 billion years to do what Joule 2.0 can do in one second. Alternatively, 1 billion people working 40 hours a week for 50 weeks per year would take about 55.9 years to do what Joule 2.0 can do in one second.
- Sixty-seven trillion sheets of paper and 1.68 trillion pens would be required to write out the results of the operations performed every second by Joule 2.0.
NETL also has created a Center for Data Analytics and Machine Learning that allows researchers to explore problems using artificial intelligence, machine learning, data mining and data analytics techniques. The center features a petascale machine designed to house, transport and process up to 37 petabytes of data, using cutting-edge algorithms developed in-house and with external collaborators. Partners for this initiative include Carnegie Mellon University, West Virginia University, Battelle, Leidos, additional industry participants and other national labs. The Center for Data Analytics is augmented by Visualization Centers in the three primary laboratory locations, in Pittsburgh, Pa.; Morgantown, W.V. and Albany, Ore.
The capabilities discussed above have been developed by NETL to address research opportunities in oil and gas, including 1) optimizing the placement of new wells in unconventional oil and gas plays; 2) improving the characterization of natural fracture networks and created fractures in tight formations; and, 3) optimizing well completion design parameters in real time.
KEY CHALLENGES
A number of key challenges were identified at a recent workshop, entitled “Real-Time Decision Making for the Subsurface,” hosted by the Wilton E. Scott Institution for Energy Innovation at Carnegie Mellon University. The workshop participants identified several barriers that could inhibit the development and use of real-time decision-making tools, including AI and ML, for subsurface applications. The most notable challenges include:
- Missing or incomplete datasets: In many cases, the data that are collected by operators is insufficient to perform the analyses needed to make significant improvements in operational efficiencies. Because of cost considerations, operators typically collect the bare minimum amount of data required to sustain operations, or data required to satisfy regulatory reporting requirements; for some of the same reasons, the data quality is also often lacking, or datasets are absent from important parameters that were not recorded/collected that may provide useful insights.
- Incompatibility of data formats: Proprietary data formats are common across the oil and gas and carbon storage industries. Because of this, when multiple operators, service companies, or vendors work together on the same site, there are significant barriers to common use of the data that are collected. Additionally, data from disparate sources, including operators working in the same field, could be out of sync in terms of timestamp, format, completeness, etc. As a result, data interpretation, preprocessing, and potential importation of missing values becomes a substantial task.
- Limitations on storing, transmitting and managing large data volumes: As novel sensing technologies have evolved, and volumes and rates of data that are collected continue to grow exponentially, the computational tools required to store and transmit such data volumes in real time have often not kept pace, such that some data that are currently collected are not used in a meaningful way. Methods for keeping track of data, as they move through a system that allows storage, backup and analysis, are lacking.
- Lack of appropriate or useful signals: In some cases, it is unknown whether signals exist within the collected data or not. Particularly, data that have often been categorized as “noise” (i.e., corrupted, distorted, or otherwise meaningless data) can sometimes contain useful information, but because of prior classification as noise, it is either discarded, not collected, or not analyzed.
- Hesitance to adopt new technologies by decision-makers: Cultural biases based on personal experience can cause decision-makers in some organizations to not adopt ML and DA approaches to improve their organizational performance.
- Limitations in labeled datasets for ML applications: Labeled datasets are required for supervised ML. Often geophysical and geoscience datasets are not labeled or are poorly labeled. An example is an earthquake catalog—some events may be mis-identified, seismic wave phases may be mis-picked, etc. Many geoscience datasets suffer from similar problems, leading to errors in the supervised learning procedure.
Recommendations. A number of recommendations came out of the workshop, including:
- Successful application of ML algorithms and big data approaches to the subsurface requires the involvement of subject matter experts (SMEs) and an outcomes-based approach. It is not uncommon for data scientists who have little-to-no geologic or reservoir engineering expertise to take broadly applicable datasets collected by the oil and gas industry, and apply mature DA and ML tools to these datasets. Unfortunately, such exercises often end in failure or reflect only marginal success.
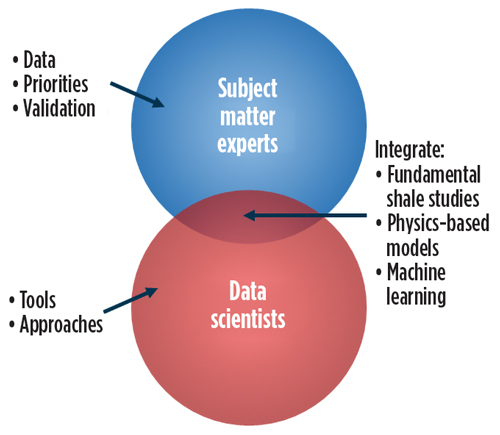
When data scientists and SMEs, who have experience in modeling and/or characterizing the subsurface collaborate (Fig. 2), the chances of success are much higher. Because subsurface problems are so complex and have high dimensionality in terms of the number of independent and dependent parameters, geoscience experts are needed, at the very least, to help shape and constrain the initial algorithms used.
Additionally, engaging SMEs can help ensure that such work is outcome-driven—i.e., that the recommendations generated from the application of ML tools are focused on improved outcomes useful to operators. Having clear outcomes as drivers of the data collection and analysis process can help identify what ML approaches are needed to solve the problem (Fig. 2), and SMEs can help identify data sources that were not originally planned as part of the effort.
- Field data should be supplemented with physics-based simulation to enable successful big-data DA and ML approaches. It’s often the case in subsurface applications that the amount and type of data collected are not comprehensive enough to do a complete analysis, based on limited data streams, alone. Analyses that rely on too little data, or on low-quality data, can easily produce misleading or erroneous results. Modeling may be needed to sample subsurface cases that are not sampled by well data, alone. When the physical properties and chemistry of a subsurface reservoir can be modeled with high-fidelity, physics-based simulators, then the results from such simulations can be used to augment field data in ML applications, Fig. 3.
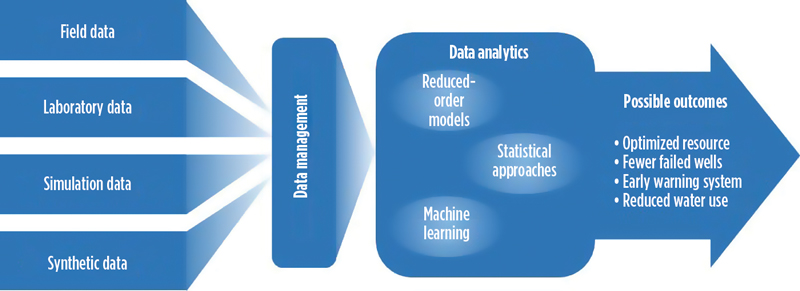
In some cases, this is done by using the simulated data to help constrain the inputs, combination of inputs, or boundaries of the DA algorithms that are used. In cases where some of the data that have been collected are of questionable quality, reservoir simulation can help provide a quality control check on the data. Additionally, reservoir simulations can generate synthetic data that can be used to train and validate ML algorithms in similar ways, regarding how field data are used. Some recent studies have shown that this approach is useful and sometimes necessary to get meaningful results from ML applications. Similarly, laboratory studies, including those focused on the physical properties and chemistry of a reservoir, could be used for training and validation procedures in the same way that simulations are used. Further, laboratory studies also can be used to ground truth simulations and to test basic physics, when it is unfeasible in situ.
Through the use of physics-based models and approaches, it will be possible to use ML approaches to significantly extrapolate from a mature and well-understood formation and into a new one within the same play or basin. By their very nature, DA approaches are only guaranteed to perform well when they are used for interpolating. However, with the combination of physics-based modeling and DA, it may be possible to use these approaches to infer key information within a given play area, where limited exploration and data collection have occurred.
- Access to large datasets, often owned by more than one operator, will be necessary to perform meaningful ML analyses. In the oil and gas industry, site characterization data are often held tightly and not shared with others, because of the value that it is perceived to have. However, in many cases, a single operator might not have sufficient data assets in a single field or play to justify the use of ML and advanced DA. Recent studies have shown that, for some applications, data from several hundred to a thousand wells may be needed before DA can inform the operator in a meaningful way.
When it makes sense, data-sharing or data-pooling should be encouraged to create larger datasets that can provide significant new insights to field operators. Even when data-pooling among operators is not necessary, researchers are going to require access to significant volumes of data from operators. For this to be successful, operators must be willing to share resources, but they also should expect to receive some type of ancillary benefit as a result of the research performed. Secure agreements that can allow researchers access to data while ensuring that proprietary data remain secure will be necessary, as new techniques are applied and developed for specific-use cases.
The use of open-source software and platform-agnostic approaches is likely to create the easiest and fastest environment for sharing such data and for the subsequent analysis, as long as those tools remain secure. Open-source software is also attractive, because it can allow oil company clients to append reservoir-specific code.
- New DM tools and approaches will be needed to enable broad application of DA and ML to subsurface applications. A wide variety of datasets need to be brought together (e.g., well logs, production logs, seismic surveys) to perform meaningful analyses. Unfortunately, data, even when of the same type, are often held in proprietary formats that are not easily accessible by others outside that organization. The challenge here is that the format for each of these types of data is wildly inconsistent by nature.
Moreover, even similar data types (for instance, well logs) may vary in constitution, albeit subtle, from one organization to the next, and even within the same organization when collected at different times or by different groups. This predicament is a significant impediment to successful data mining and ML absent of diligent data preprocessing. If each data type had a standard format or even a few standard formats, that would make it much easier to meaningfully share data and information from one organization to another (e.g., operators, service companies, consultants, researchers). Standardization also would likely enable faster development of useful ML tools that can be more broadly tested and applied to industry problems.
Implementation. The Joule computer and the associated structure have enabled NETL to target AI and ML research in a number of areas, including high-priority-use cases for DOE listed below:
- Field development: Optimizing the location, placement, trajectory and spacing of new production wells.
- Fracture modeling: Modeling natural fracture networks and estimating fracture propagation.
- Completion design: Optimizing completion parameters, such as injection pressures and times, and fluid composition, in real time using downhole data.
- Enhanced oil recovery: Optimizing secondary/tertiary recovery plans, including flood type and well placement.
- Well design: Determining the hierarchy of well/completion variables, interactions between variables, and optimizing designs.
- Geosteering: Geosteering autonomously through a reservoir, based on real-time data and consistently hitting reservoir target zones.
- Reservoir modeling: Building reservoir models that rapidly test large numbers of field development plans and update models in real time, using production data.
- Reservoir characterization: Determining a reservoir’s geologic features and correlating geologic layers for improved reservoir characterization.
- Well logging: Identifying outliers, hidden patterns, and reservoir properties from downhole sensor data and reconstructing well logs.
- Frac hits: Developing new methods for identifying areas at risk for reservoir frac hits.
A significant number of AI/ML projects are underway or planned within NETL, primarily under the Science Based Machine Learning to Accelerate Real Time Decision Making (SMART) initiative.
A representative list of SMART and other projects is discussed below.
The first project is the development of real-time forecasting, based on the collection of tailored downhole data to increase production. The project is underway in the western Marcellus area. Key to success is gaining access to data from the MSEEL project, which includes stage-specific information along the horizontal producer as operational production parameters are changed, as well as key geologic and completion parameters.
In addition, data collection is underway to acquire data sets from 136 horizontal wells and 1,140 vertical wells in the Permian basin, in addition to 250 mi2 of proprietary seismic data and access to sample wellhead fluids and fracturing fluids. The project will conduct real-time visualization of fracture networks, both natural and induced.
The goals of the projects are, first, to enable just-in-time visualization (days to weeks, instead of months to years)and real-time forecasting and, second, to enable real-time forecasting to inform decision-making (the ability to make decisions in a few minutes to hours rather than days to weeks).
A number of other AI/ML projects are being planned or under consideration within NETL, in addition to Funding Opportunity Announcements (FOA) seeking relevant R&D project ideas, and their subsequent performance, by industry and academia. These efforts will be partially funded by NETL. For further information, visit www.netl.doe.gov.
- Digital transformation/Late-life optimization: Harnessing data-driven strategies for late-life optimization (March 2024)
- The reserves replacement dilemma: Can intelligent digital technologies fill the supply gap? (March 2024)
- Digital tool kit enhances real-time decision-making to improve drilling efficiency and performance (February 2024)
- Digital transformation: Digital twins help to make the invisible, visible in Indonesia’s energy industry (January 2024)
- Digital transformation: A breakthrough year for digitalization in the offshore sector (January 2024)
- Quantum computing and subsurface prediction (January 2024)

